Introduction

We provide a Starter Dataset generated by Omnidata Pipeline from some existing 3D datasets. It contains more than 14 million images from over 2000 spaces with 21 different mid-level vision cues per image. The dataset covers very diverse scenes (indoors and outdoors) and views (scene- and object-centric).
Sample Data
If you want to download the dataset, check out the download page. But if you want to just look at the data first, we provide a small sample of a single random building in our GSO + Replica dataset split, which is created by scattering Google Scanned Objects around Replica buildings using the Habitat environment. This is only a sample scene (with mostly object-centric views) from over 2000 scenes available in the full dataset.
You can download and untar the sample data with the following command:
wget https://drive.switch.ch/index.php/s/MkygxW0WLiLKsNz/download
tar -xf download
Now the sample dataset is available in the folder omnidata_sample_dataset.
| Sample Data (GSO+Replica) |
|---|
 |
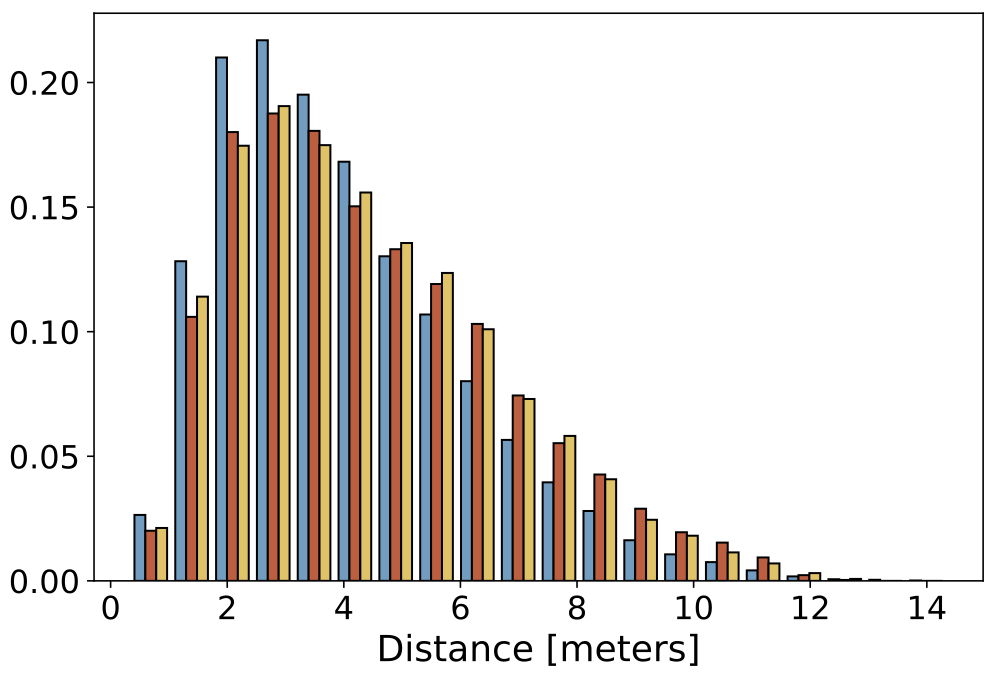
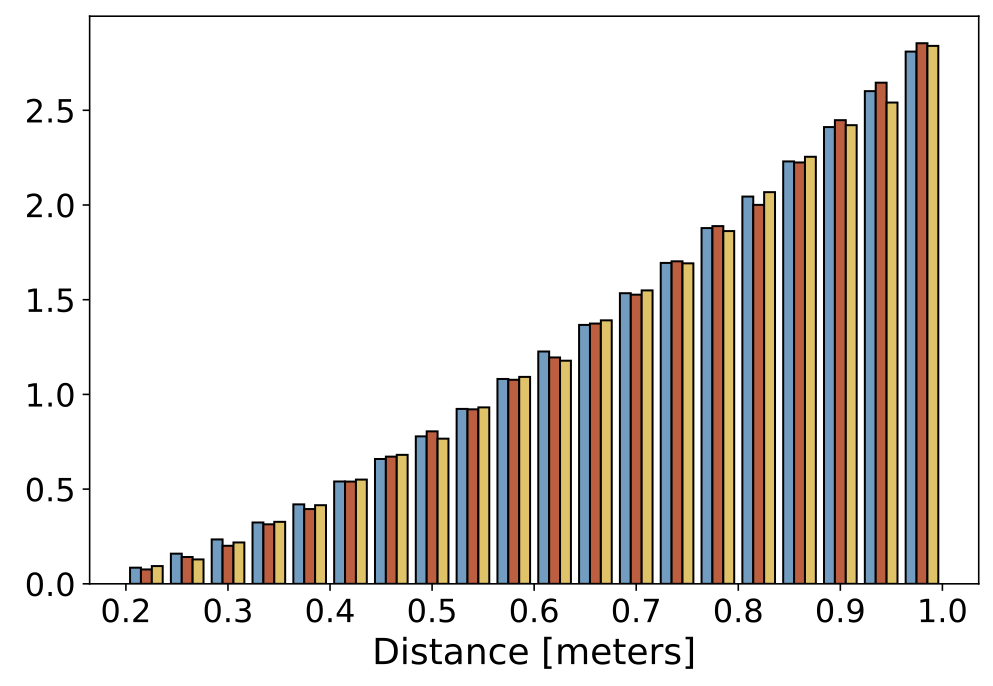
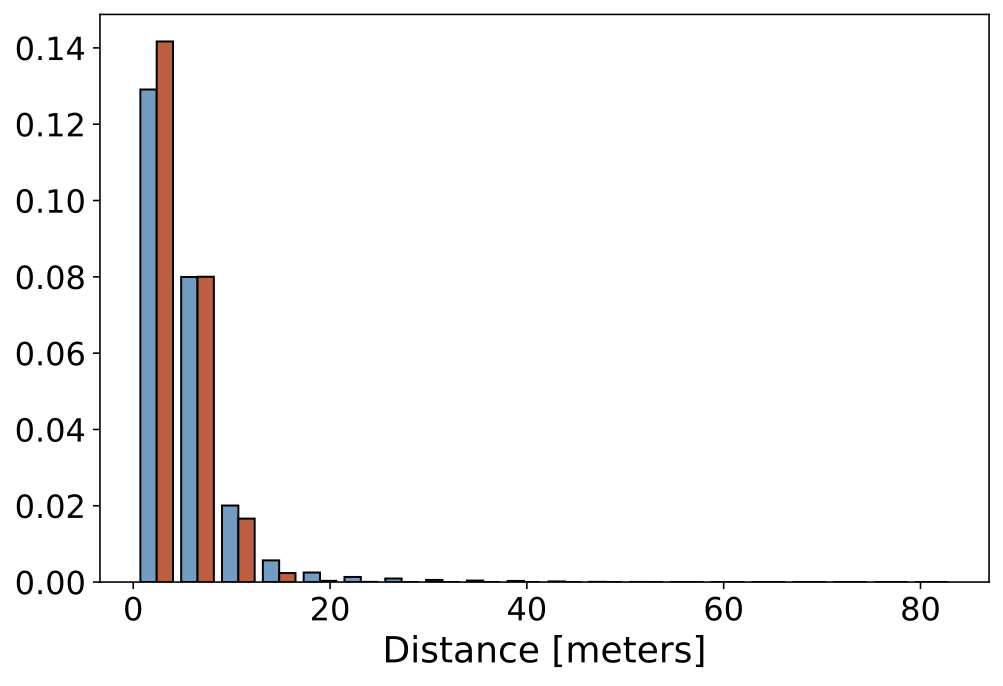
Data Statistics
To see how these distributions affect image content, check out our online demo that lets you experiment in the browser.
Below we show some static histograms:
 |
Taskonomy | Replica | GSO+Replica | HM3D |
|---|---|---|---|---|
| Field of View | 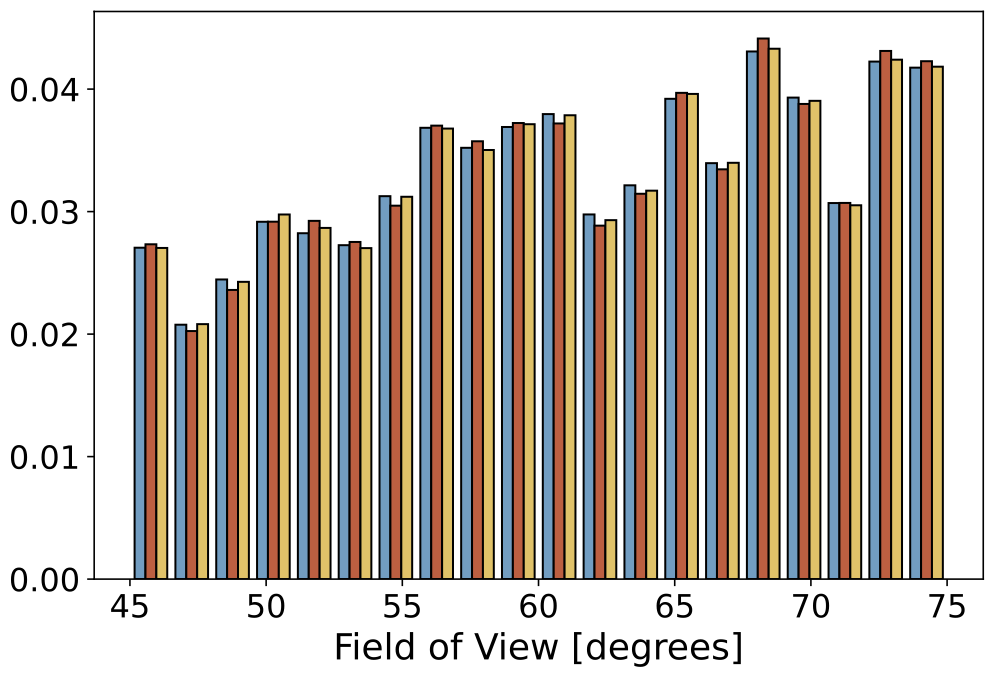 |
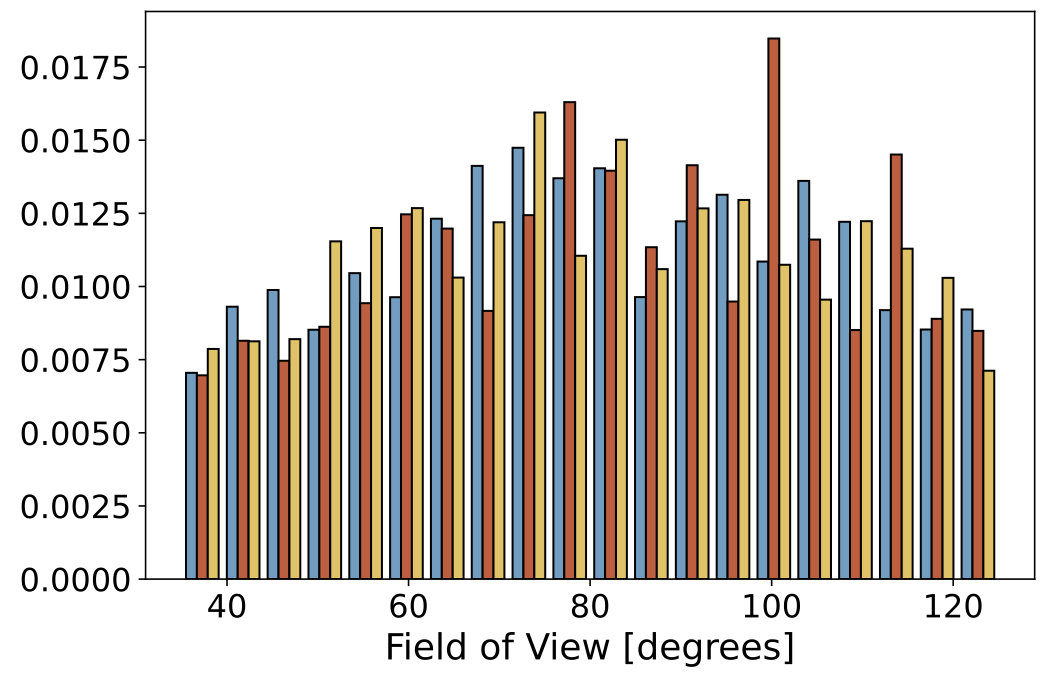 |
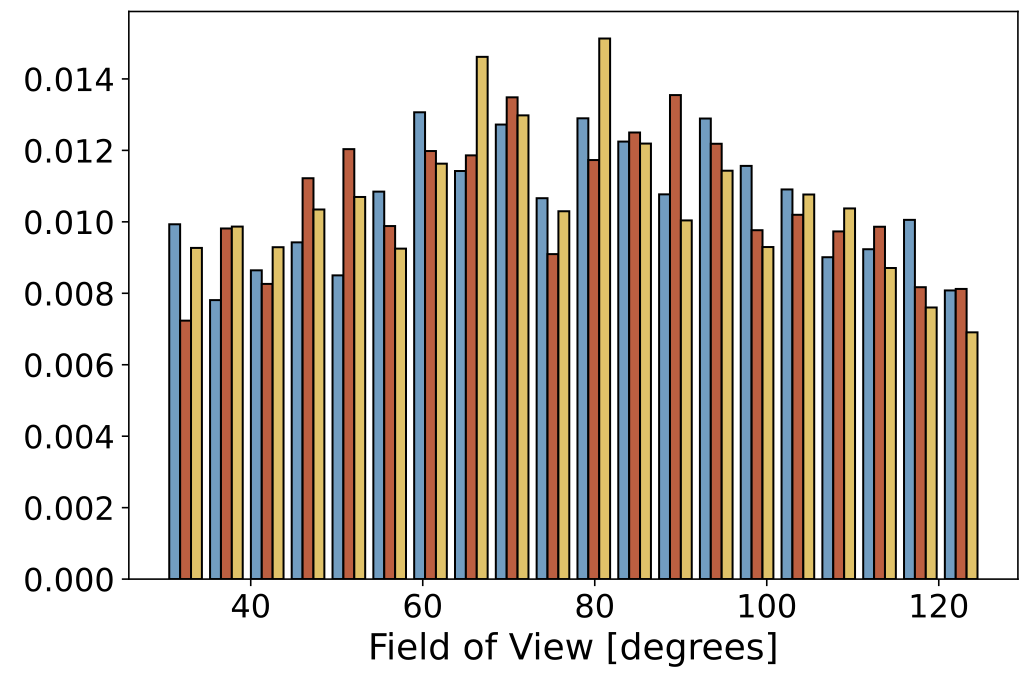 |
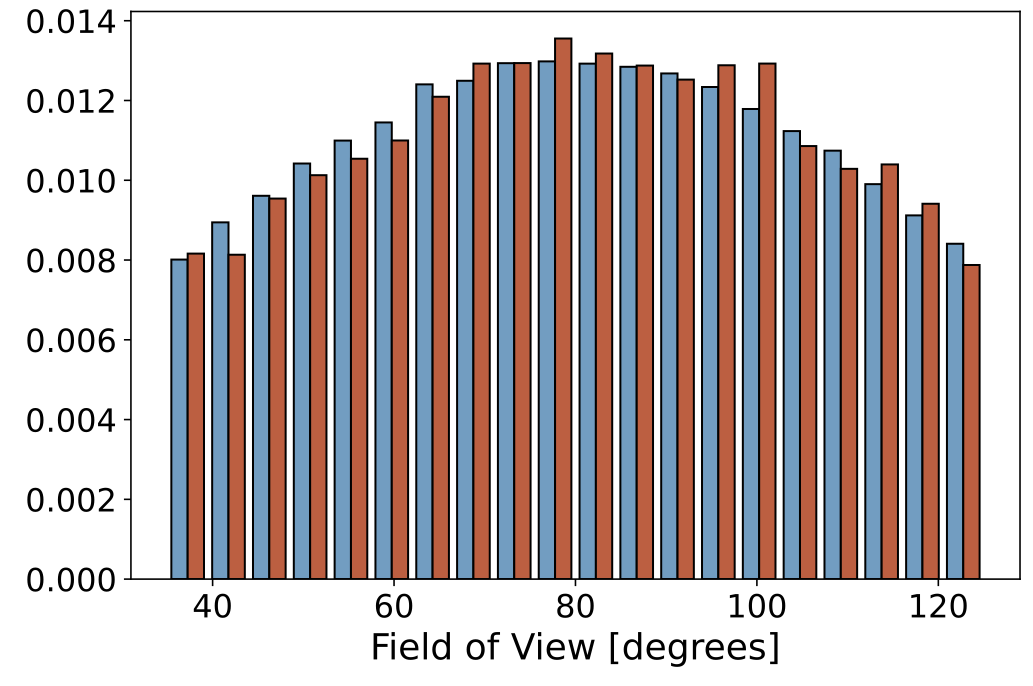 |
| Camera Pitch | 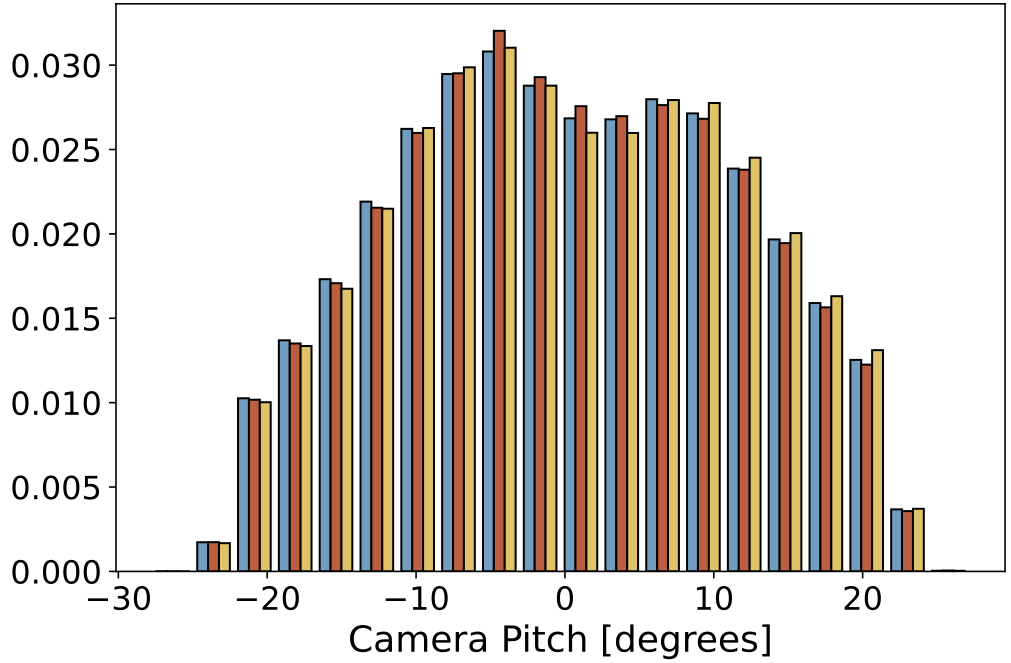 |
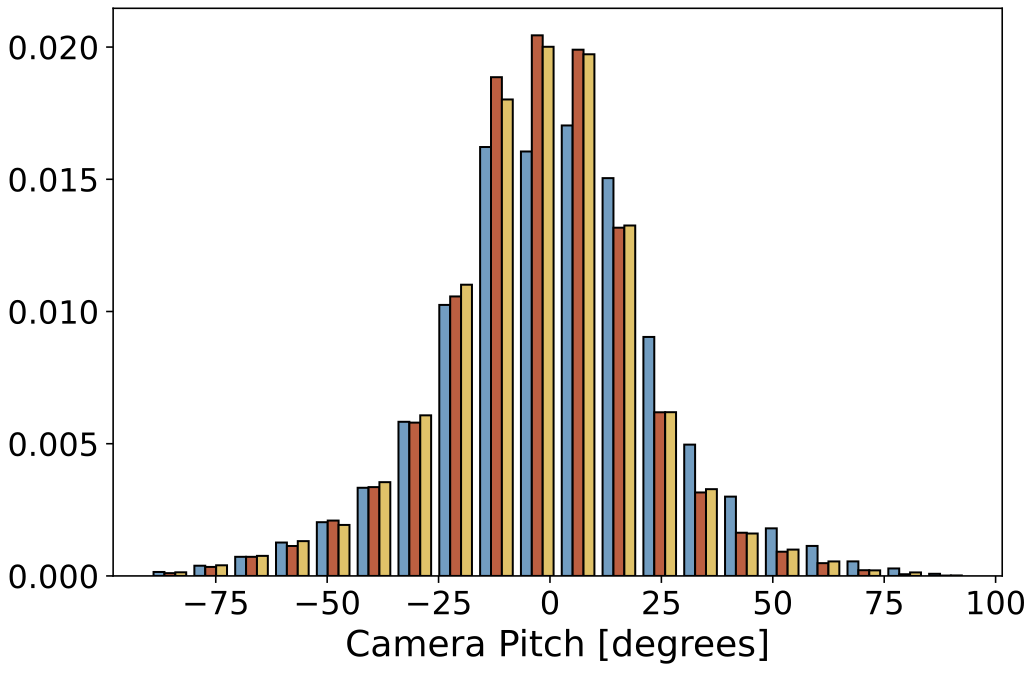 |
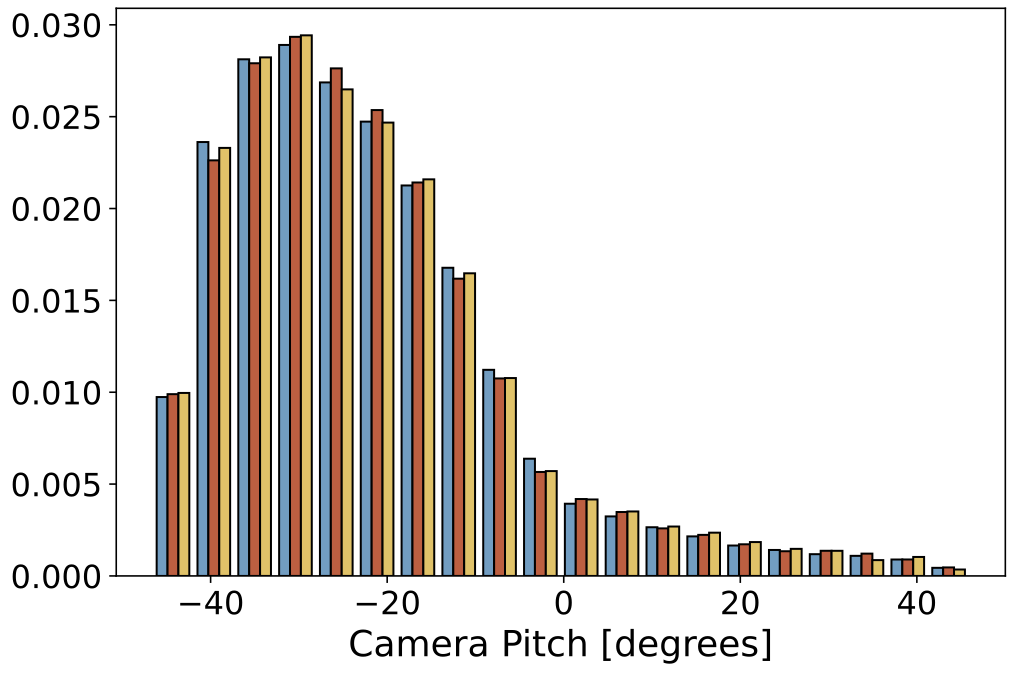 |
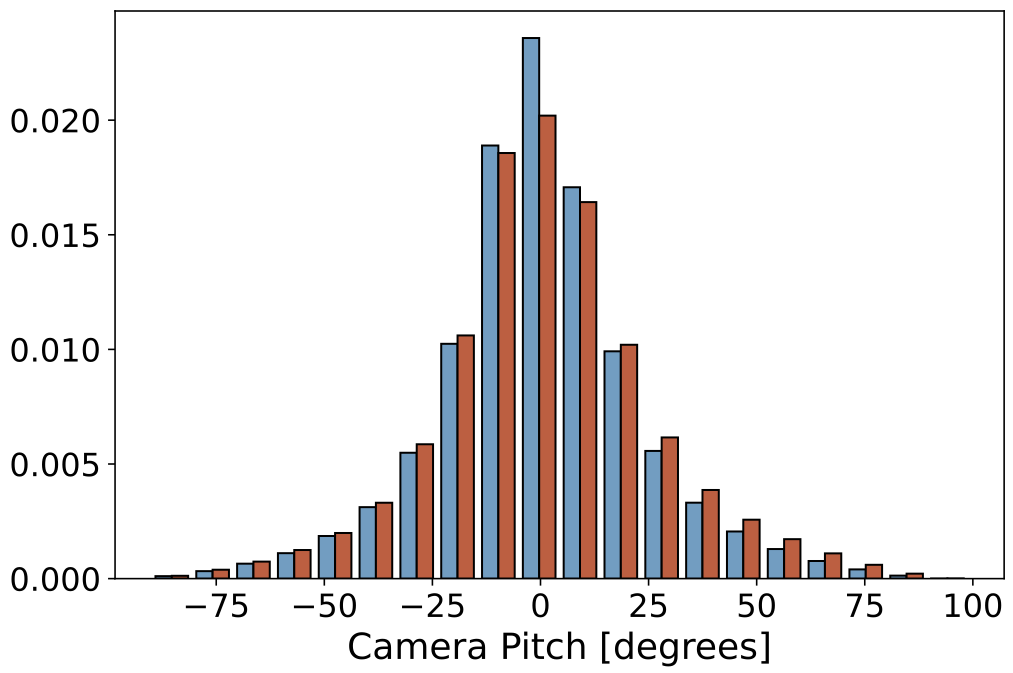 |
| Camera Roll | 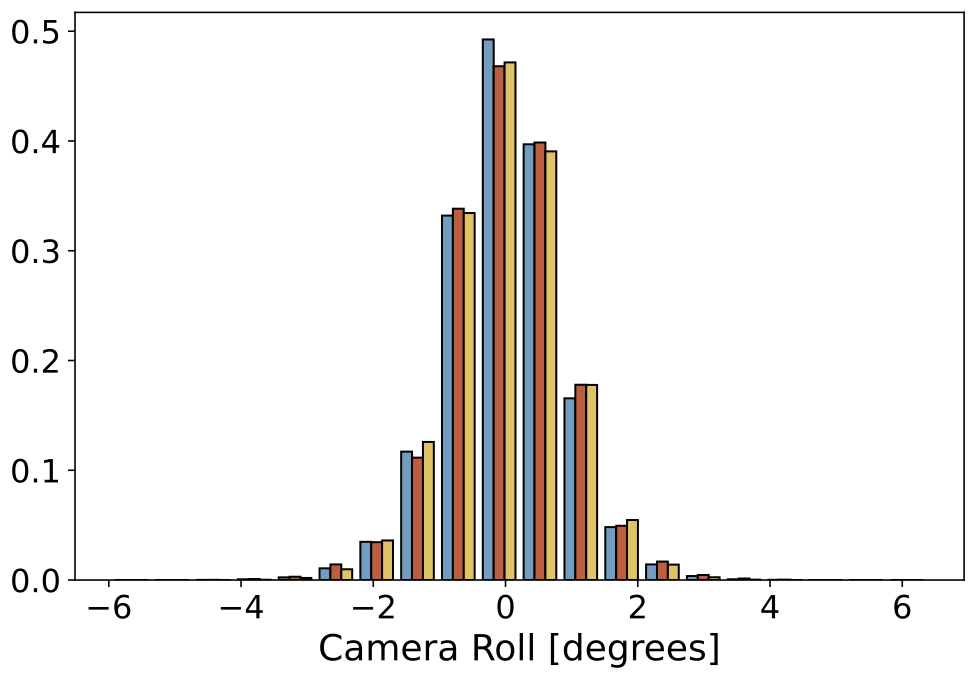 |
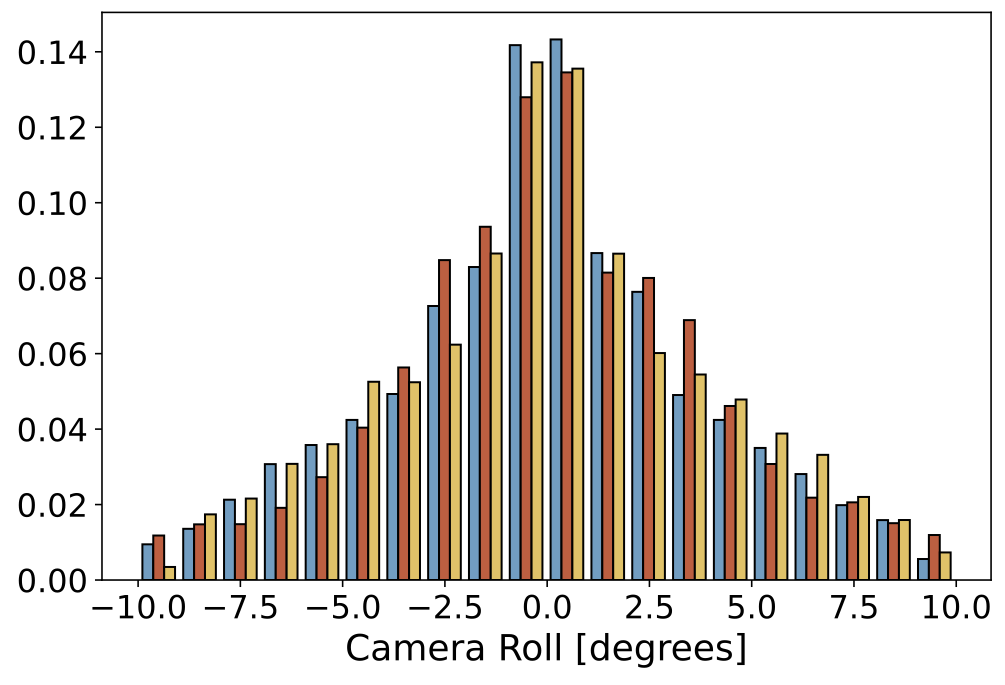 |
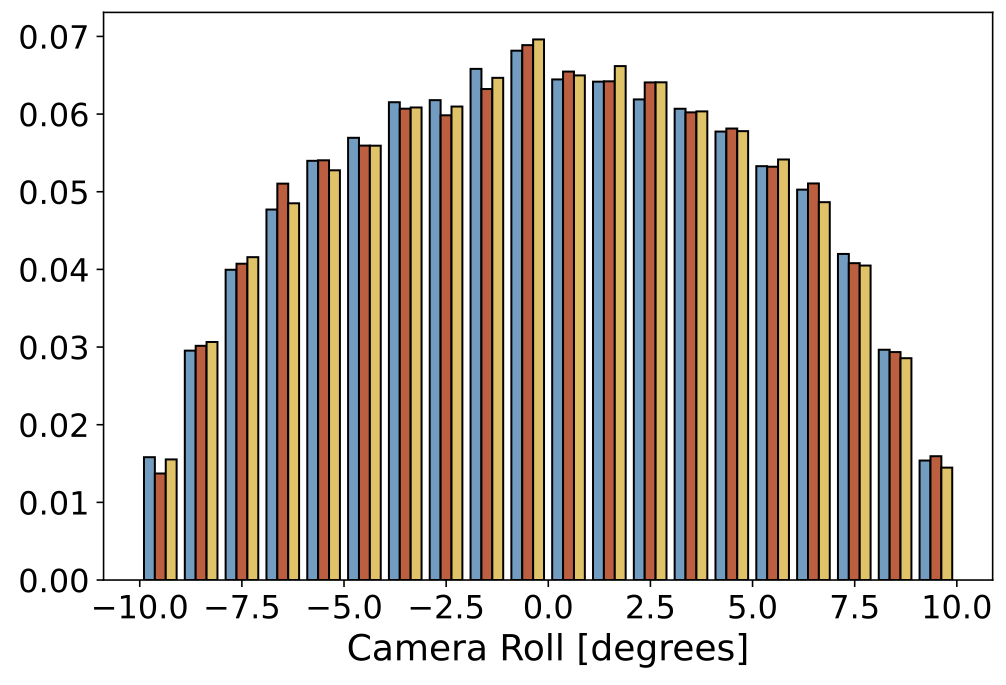 |
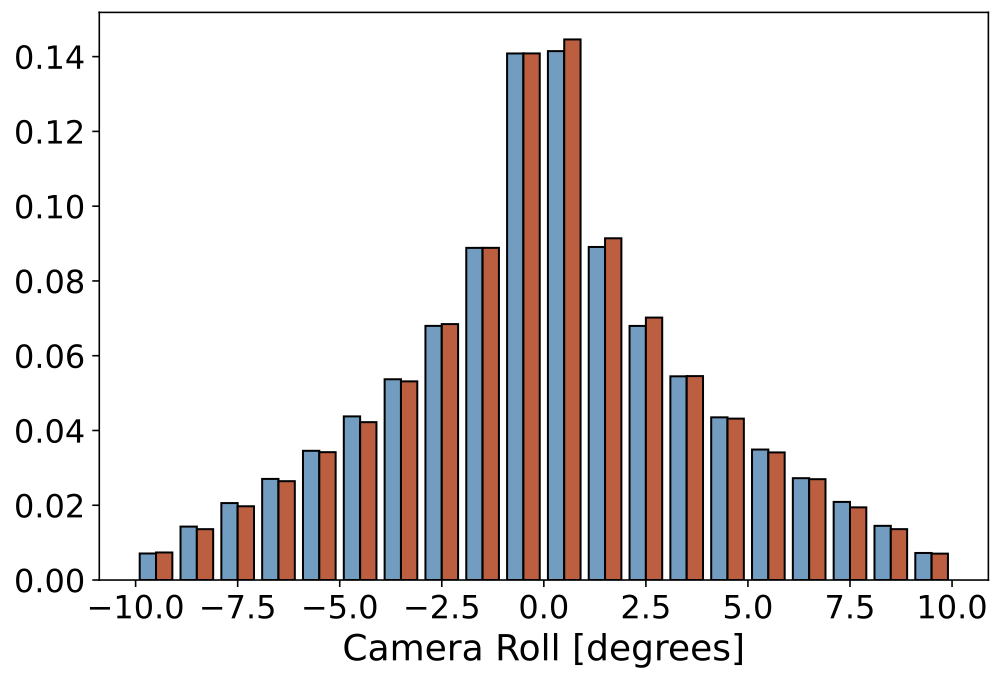 |
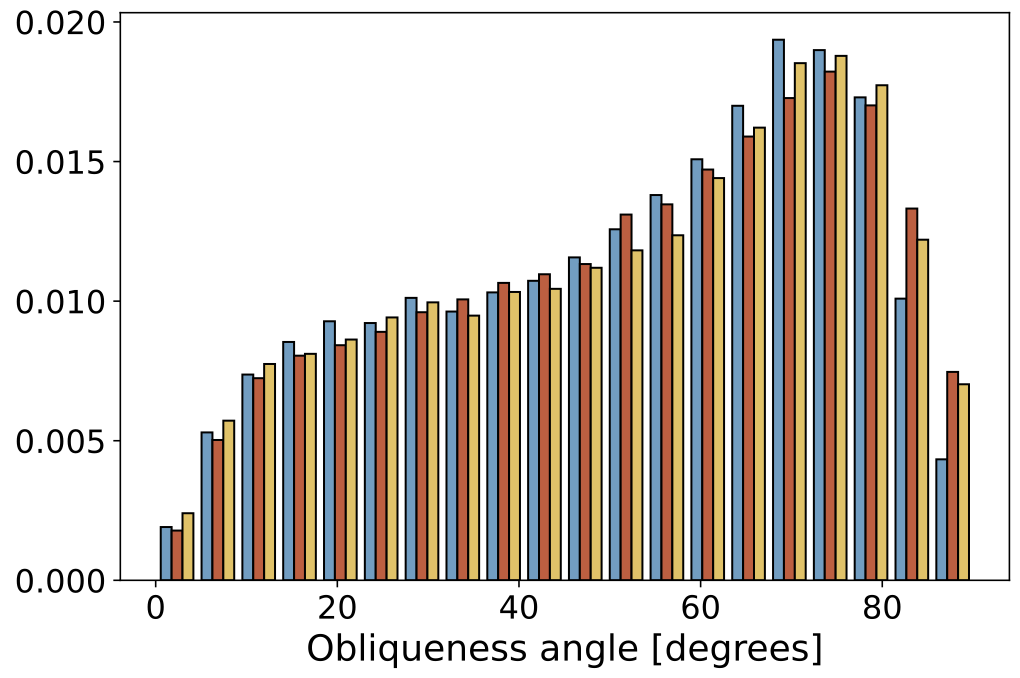
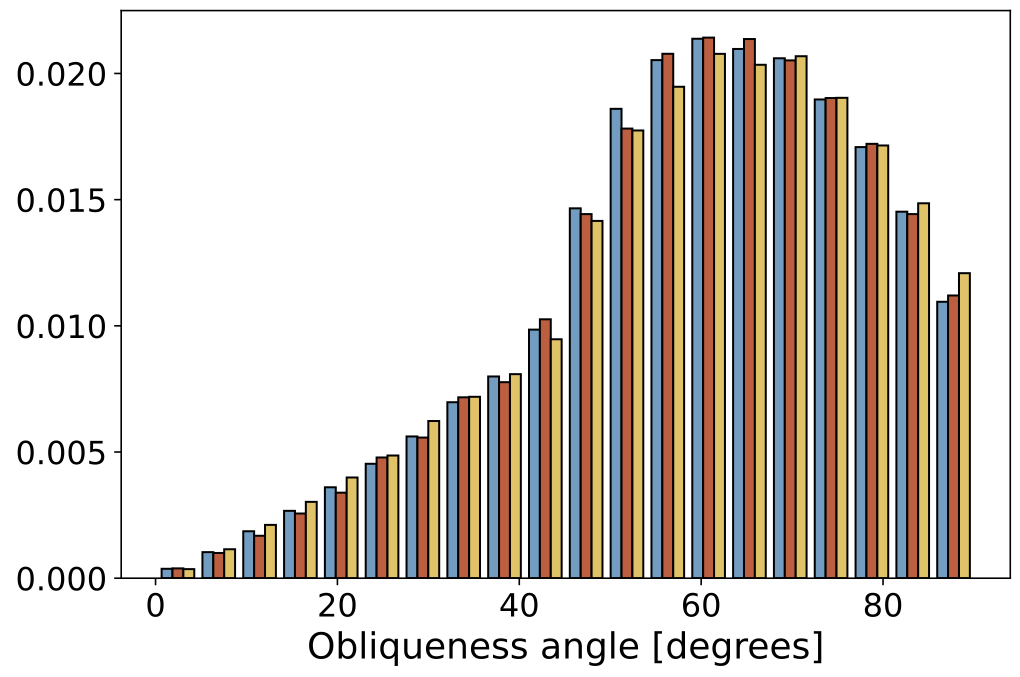
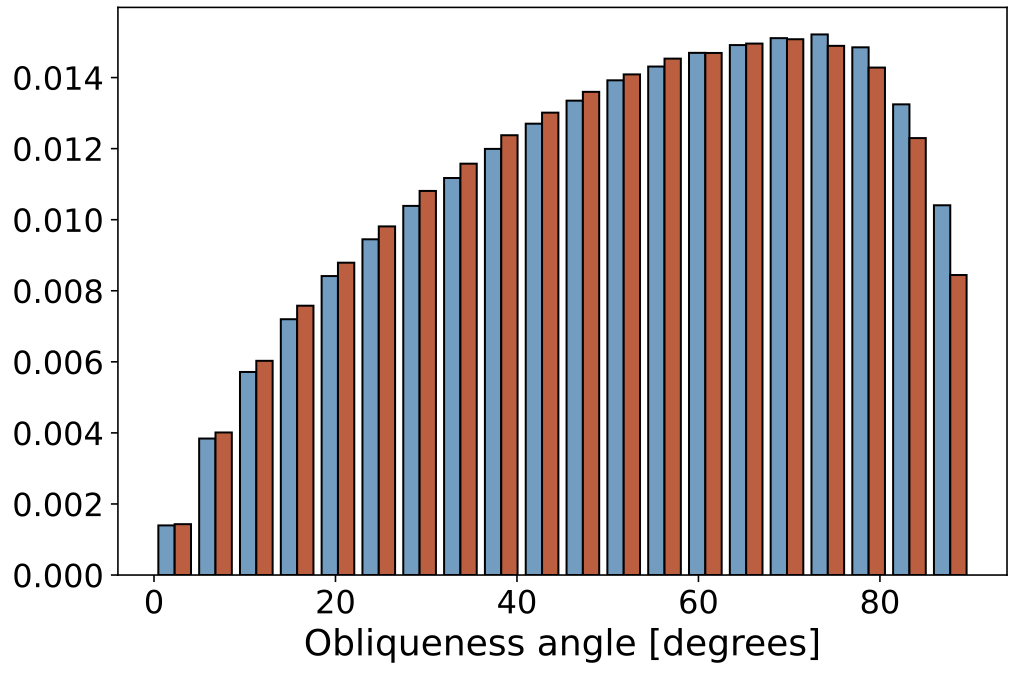
| Obliqueness Angle | 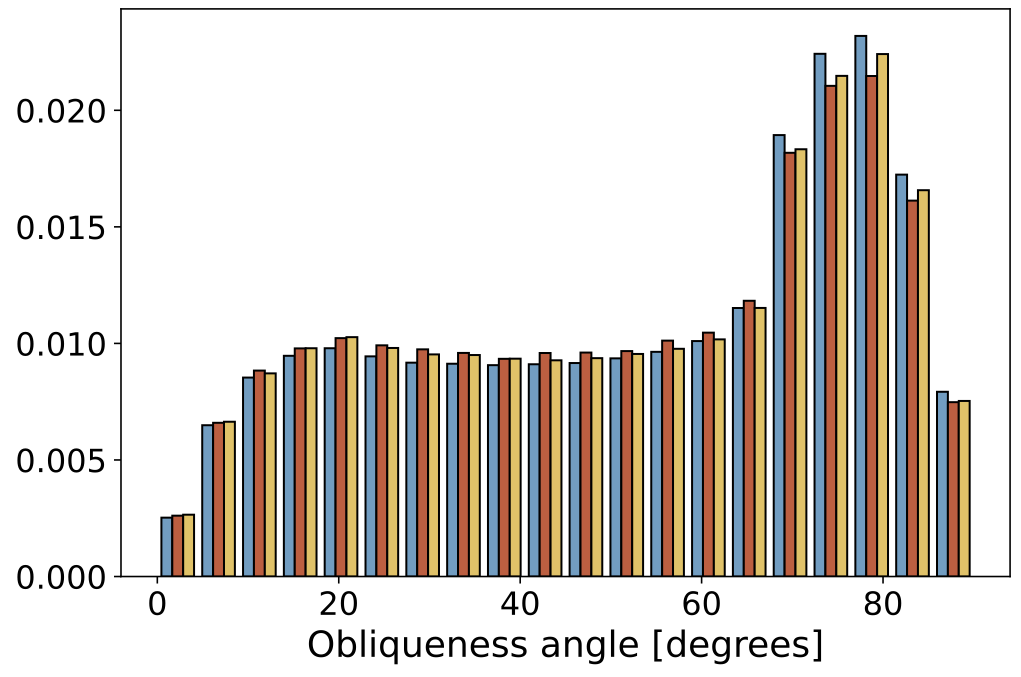 |
 |
 |
 |
| Camera Distance | 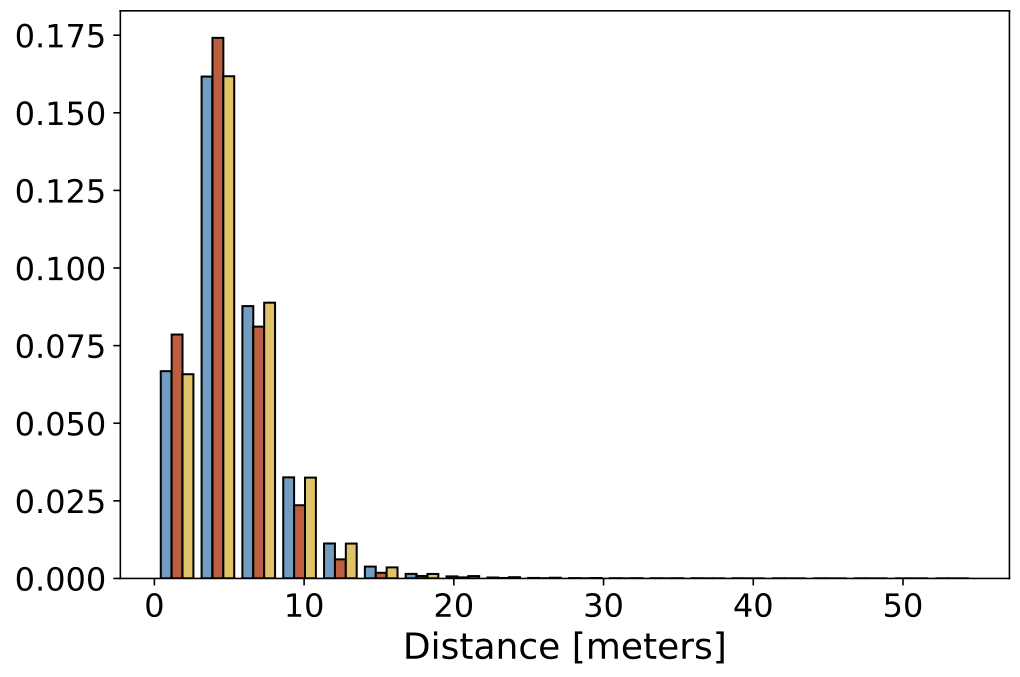 |
 |
 |
 |
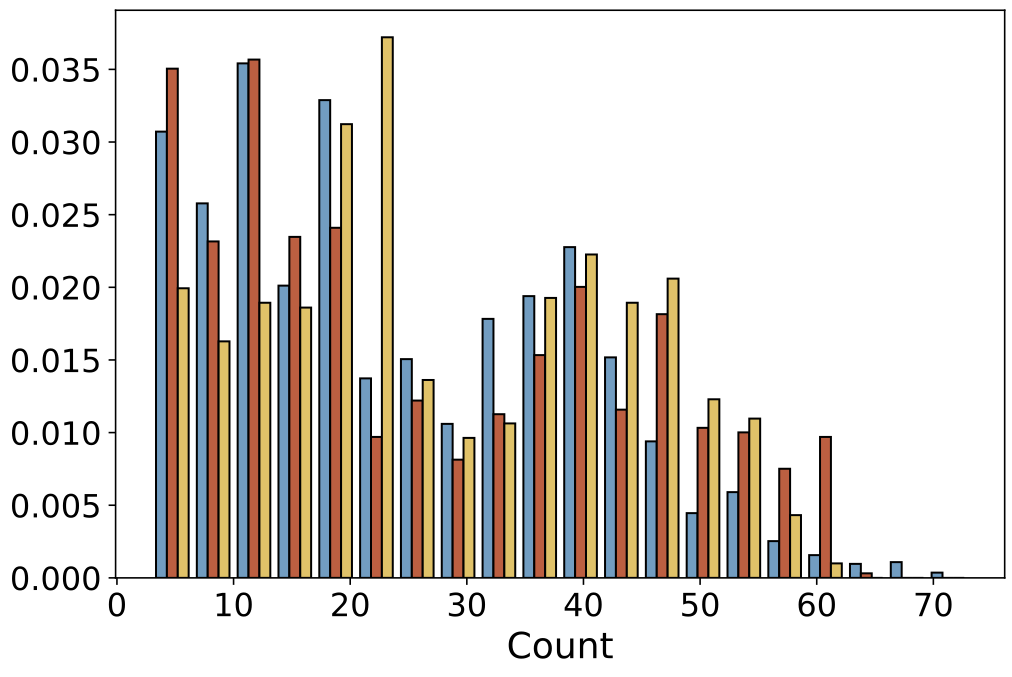
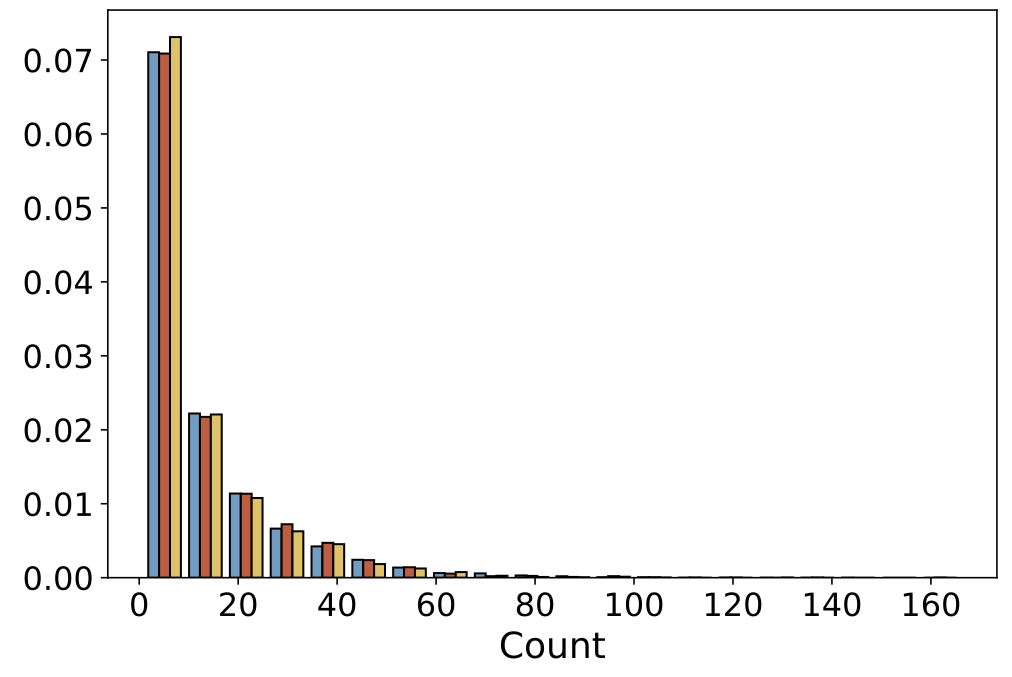
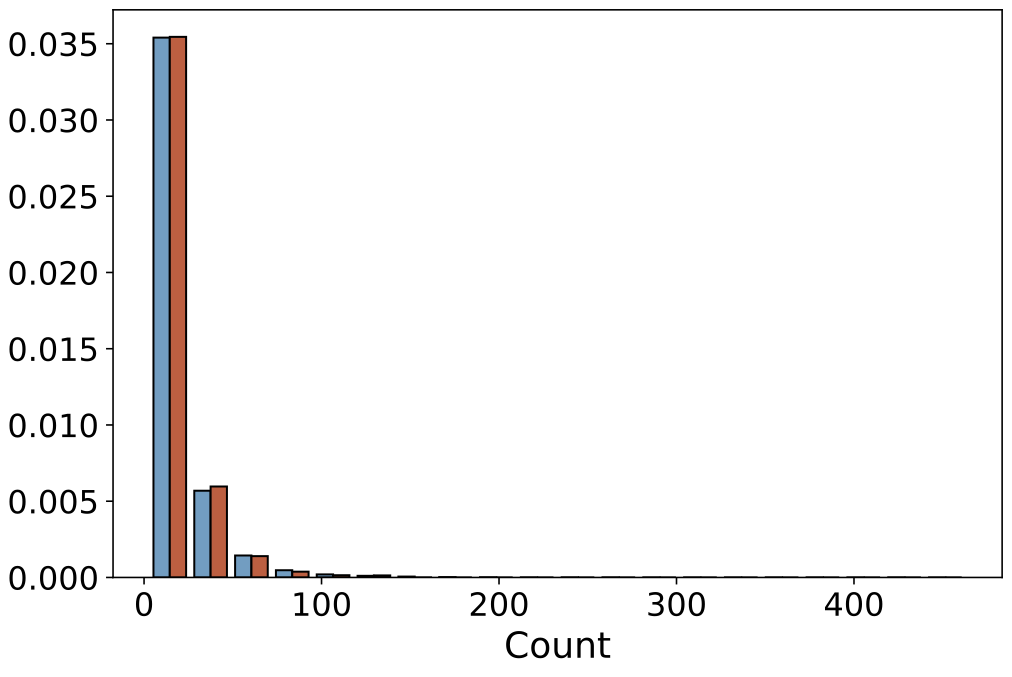
| Views per Point | 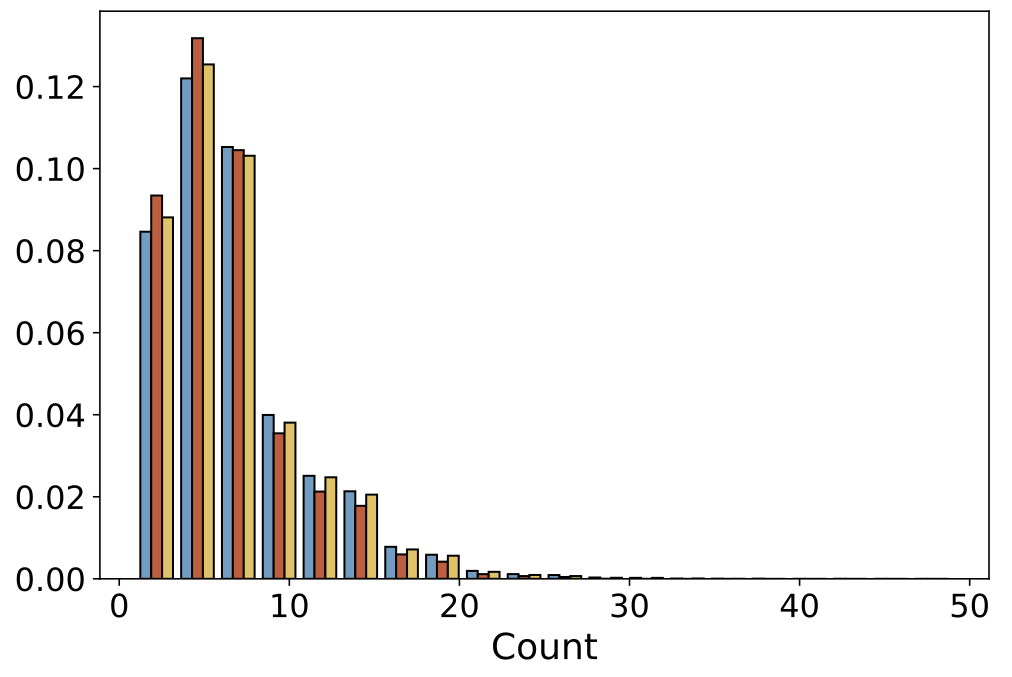 |
 |
 |
 |